

| 一、 问题的提出 在现在多重、瞬息万变的竞争环境中,大型组织,特别是百年企业,其生存和发展能力的重要因素不是企业的现有土地、资本的多少,而是企业是否具有战略价值的人力资源管理模式,而战略人力资源规划的重要性更是不容忽视的。企业人力资源需求预测是根据企业的发展规划和企业的内外部环境,采取适当的预测技术,对人力资源需求的数量、 质量和结构进行预测。它做为人力资源规划制定的第一步,其预测方法的合理性及预测结果的有效性决定了该企业人力资源规划的科学性。 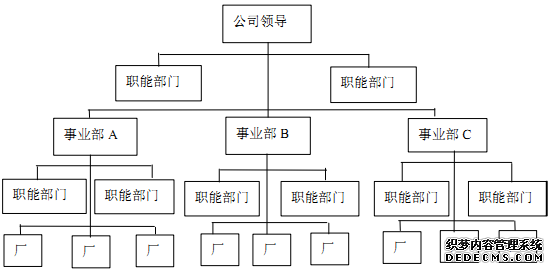
图 1 事业部制组织结构
事业部制组织结构又称为 M 型组织结构(MultidivisionalStructure),是现代组织在管理体制上由集权化向分权化转化的产物。其特点是组织经营过程中按照不同产品和地区建立起经营事业部,做为一个独立的利润中心,实行“自主经营,独立核算。这种组织结构形式按照 “集中政策,分散经营”方针,公司总部负责研究和制定整个公司的各种策,各下属事业部在总部制定的政策下,可以根据事业部自身的发展需要自主设置组织结构。这有利于现代组织形成强有力的决策机构和灵活主动的执行机构, 并适应复杂多变的环境。这种组织结构形式一般适用于组织规模较大、 产品种类较多、各产品之间的工艺差别较大的现代大型联合企业。对于大型事业部组织,其人力资源需求预测需要综合考虑各方面因素。大型事业部组织人力资源需求预测的好坏直接决定了其人力资源规划的成败。基于此,本文在相关理论分析的基础上,对大型事业部制组织人力资源需求预测提出了相关建议及操作说明以供借鉴。二、 人力资源需求预测的流程与方法简述 人力资源需求预测是人力资源规划中最重要、最复杂的方面之一。我们将从人力资源需求预测的流程及方法三个角度系统阐述如何进行人力资源需求预测。其中,需求预测的方法是否适用于公司直接决定了人力资源需求预测的有效性。 (一) 人力资源需求预测的流程 一般而言,人力资源需求流程的步骤如下:(1)调查、收集和整理涉及企业战略决策和经营环境的各种信息。(2)根据企业或部门实际确定其人力资源规划的期限、范围和性质。建立企业人力资源信息系统,为预测工作准备精确而详实的资料。(3)在分析人力资源供给和需求影响因素的基础上,采用以定量为主,结合定性分析的预测方法对企业未来人力资源供求进行预测。(4)制定人力资源供求平衡的总计划和各项业务计划。通过具体的业务计划使组织对人力资源的未来需求得到满足。 (二) 人力资源需求预测的方法 根据美国斯坦福研究所的统计,目前人才预测的方法多达150多种,国内外常用的人才总需求预测方法可分为宏观预测和微观预测两大类,宏观预测又分为定量和定性预测法。其中常用的定量预测方法包括趋势分析、比率分析、散点分析及计算机预测等;宏观定性预测包括德尔菲法、经验预测法、描述法等。本文下面对一些常用的方法给予介绍。 1.趋势分析。趋势分析(Trend Analysis)就是首先通过分析企业在过去五年左右时间中的雇佣趋势,然后以此为依据来预测企业未来人事需求的技术。例如,组织可以综合统计企业在过去五年中每年年末的雇员数量,或者这些年年末的各类人员数量(如销售人员、生产人员以及行政管理人员等),其目的在于确定今后有哪些趋势会继续发展下去。趋势分析做为一种初步预测是很有价值的,但仅有它还远远不够,因为雇佣水平很少会只由过去的状况决定。其它一些因素(如销售额和生产率的变化等)也将影响你未来的人事需要。 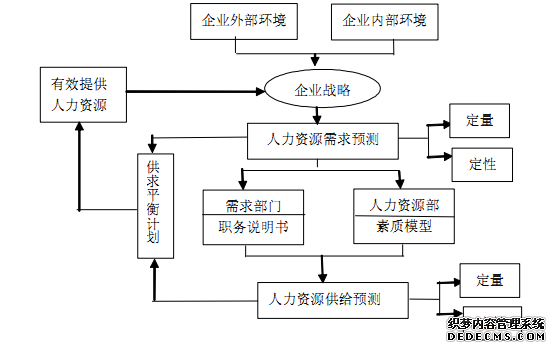 图 2 人力资源需求预测流程 3.散点分析。散点分析(Scatter Point)是通过确定企业的业务活动量和人员水平是否相关来预测企业未来人员需求的技术。如果两者相关,那么,一旦可以预测出企业的业务活动量,也就能预测出企业的人员需求量。当考虑两个或者两个以上因素对人力资源需求的影响时, 便是多元线性回归预测法。这种方法相对比较复杂,一般只在管理基础比较好的大型企业里采用。例如,在确定医院的规模(以床位数量为依据)与需要的护士人数之间是正相关后,便可根据医院床位预测出医院大约需要的护士数量。 4.经验预测法。经验预测法有“自上而下”和“自下而上”两种方式,这两种预测方式亦可综合使用。“自上而下”就是由公司经理先拟定出公司总体的用人目标和建议,然后由各级部门自行确定用人计划;“自下而上” 就是由直线部门经理向自己的上级主管提出用人要求和建议,征得上级主管的同意。 
5.德尔菲法。德尔菲法一般分以下几轮进行:首先,做预测筹划工作,这包括确定预测的项目、设立负责预测组织工作的临时机构、选择若干熟悉预测项目的专家;然后,由专家进行预测,在预测过程中,专家之间不能互相讨论或交换意见;后将专家的预测结果收集起来统计分析,再将综合的结果通知各位专家,以进行下一轮的预测;如此反复经过几轮,专家的意见趋于一致;最后我们将预测结果以文字或图表形式表现出来。刘善仕(2002)运用案例研究法得出德尔菲法在动态环境的人力资源需求短期预测中的有效性要高于其它统计方法。
三、 大型事业部制组织下属事业部的分类 由于大型事业部制组织(本文假设所研究的事业部总部无经营相关业务)下属的不同事业部所属地区经济社会条件状况都有一定的差距,其发展速度、规模及面临的发展机遇等各不相同,因此,总部应充分考虑各个下属事业部所处的地域条件及本身的发展状况,采取不同的管理策略。由此产生的一个重要问题是,如何对各下属事业部进行分类管理呢?如果采用一刀切的管理模式,组织可能会无法瘦身,人员也会不断递增,公司总部———尤其是人力资源管理部门将疲于奔命,止于事务性而不是战略性的人力资源管理,为此,我们建议根据下属事业部所提供的历年业务量指标数据及员工总数,首先通过两种统计方法,即聚类分析法和描述性统计分析法对公司进行分类,为组织变革提供科学的依据。 (一) 聚类分析法 聚类分析是一种建立分类的多元统计分析方法,它能够将一批样本(或变量)数据根据其诸多特征,按照性质上的亲疏程度在没有先验知识的情况下进行自动分类,生成多个分类结果。所谓 “没有先验知识” 是指没有事先指定分类标准; 所谓 “亲疏程度” 是指在各变量 (特征)取值上的总体差异程度。每个类属内部的个体在特征上具有相似性,不同类别之间的个体特征差异性较大。其中的系统聚类分析也叫分层聚类分析,是目前国内外实际应用得最多的一种方法。举例如下: 假设有 5 家电视公司,在毛利润和销售量两个指标上的平均分如表2所示,主观上可以加以分类,但是更为客观的方法是聚类分类。 
根据表2中的数据,很明显可以看出若将它们分成两类,则A公司和B公司是一类,C公司、D 公司,E 公司是另一类;若将它们分成三类,则A公司和B公司是一类,D公司和 E 公司为一类,C 公司自成一类。得到如此分类结果的原因是:在两方面的评分中,A 公司和 B 公司分数较为接近,D公司和E公司较为接近。A公司和E公司之所以没被分在一起,是由于它们的分数相差较远。可见,这种分类结果是在没有指定任何分类标准下完全由样本数据出发而形成的分类,而系统聚类分析的分类思想与上述分类是一致的,这样的分类更加科学与客观。
我们按照这方法在研究公司的分类情况时运用了系统聚类分析法,即综合考虑下属事业部发展的主要影响指标,如援用各个下属事业部各业务量指标数据、员工月平均数据与业务量指标数据、员工月平均数的平均增长率等指标进行聚类分析。聚类分析 SPSS 操作步骤演示图如下所示: (1) 在SPSS工具栏中选择 “Analyze” → “Classify” → “HierarchicalCluster Analysis” ; (2) 将所有主要影响指标放入 “Variables” 一栏, 将下属事业部放入 “Label Cases by” 一栏, 具体见下图: 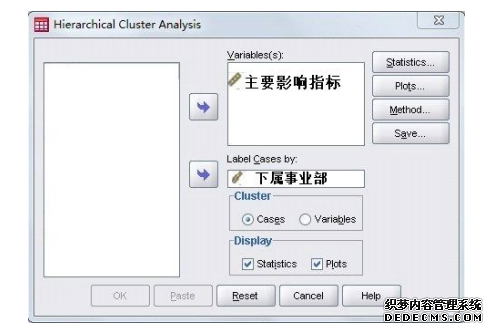
图 3 聚类分析过程
(3)“Plots”中选择“Dendrogram”(树状图);“Method”中,聚类方法选择“Ward 法”,“Interval”选“Squared Euclideandistance”;点击“Continue” ;
(4)点击“OK”,生成分类结果(分类结果可主要看两个图形:冰状图和树状图) 。 (二) 描述性统计分析法 我们首先对公司的业务量指标数据进行分析处理,得到各下属事业部历年业务量月指标数据及员工人数的月均值,并据此做出柱形图。通过柱形图,我们可以直观地观察各下属事业部的业务量指标数据差距及其发展情况,以达到和聚类分析法分析结果之间的交叉验证。柱形图的分析尽管使用主要的经济指标,也可从增幅或者发展速度方面的指标将事物加以分类,但是当指标增多时,就难免出现不一致的情况。因此,在统计上,上文分析的聚类分析方法更为常用。通过分类,有利于我们抓住重点,从总体上去把握事物,找出解决问题的方法。 四、 大型事业部组织人力资源需求预测方法的选定及判定 制定人力资源规划需要科学的预测,而科学预测的首要与关键问题是做好人力资源需求预测,有效的人力资源需求预测需要量化方法支持。本文之所以建议采用多元逐步回归模型做为大型事业部组织人员数量预测方法,正是要为公司人力资源规划提供关键支持,具体依据如下: (一) 多元回归模型的选定 回归分析是一种处理变量的统计相关关系的一种数理统计方法。回归分析的基本思想是: 虽然自变量和因变量之间没有严格的、确定性的函数关系, 但可以设法找出最能代表它们之间关系的数学表达形式。 多元回归模型研究的是多个自变量与一个因变量的关系,按照选入变量顺序的不同, 可分为前进法、后退法及逐步回归法。前进法的思想是由少到多,每次增加一个,直至没有可引入的变量为止,但前进法不能反映引进新的自变量后的变化情况, 原来显著的自变量, 在引入其他自变量后可能变得并不显著,没有机会将它剔除。后退法则一开始把全部自变量引入回归方程,计算量很大,而且一旦某个自变量被剔除,它就再也没有机会重新进入回归方程。我们建议采用多元逐步回归法, 其基本思想是有进有出,具体做法是将变量一个一个引入,当原引入的变量由于后面变量的引入变得不再显著时,要将其剔除。这样就避免了前进法和后退法各自的缺陷,保证了最后所得的回归方程是最优回归方程子集。 大型事业部制组织需要具有与强大对手抗衡的实力,又要有对经常变化的市场做出迅速反应的经营灵活性,其人力资源需求更是受到外部环境和内部环境多种因素的影响。一般情况下,这些因素可以通过多年积累的历史资料分析而得。 为了综合考虑多种影响因素,我们可以通过公司组织结果因素(业务量等)与人力资源需求关系的分析与提取,并运用多元回归模型加以预测,从而实现对大型事业部制组织人力资源需求的预测。 (二) 多元回归模型的判定 如果模型能通过下面的检验,就可以应用这些影响因素(输入变量)对企业人力资源需求(输出变量)进行预测。 1.拟合优度检验。回归方程拟合优度检验就是检验样本数据聚集在回归直线周围的密集程度, 从而判断回归方程对样本数据的代表程度,反映的是总的回归效果,一般用判定系数 R2表示。 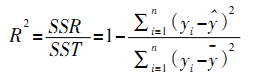 其中,R2越接近于1,说明回归方程的拟合程度越高。 2.回归方程的显著性检验。回归方程的显著性检验是对因变量与所有自变量之间的线性关系是否显著的一种假设检验,一般用 F检验。即: 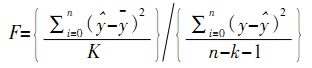 其中,n为样本数;k为自由度。根据计算出来的结果进行分析,如果计算出来的相伴概率 p<琢 (给定的显著水平),就说明自变量与因变量存在显著的线性关系回归方程显著,反之回归方程不显著。 3.回归系数的显著性检验。回归系数的显著性检验是检验各自变量对因变量的影响是否显著, 从而找出哪些自变量对因变量的影响是重要的, 哪些是不重要的, 一般用 t检验来实现。 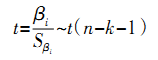 其中,n 为样本数;n-k-1 为自由度;为回归系数的标准误差。根据计算出来的结果进行分析,如果相伴概率p<琢(给定的显著性水平),就认为该自变量与因变量之间存在显著的线性关系,应该保留在方程中,反之则应该剔出。 五、 大型事业部制组织人力资源需求预测方法的具体操作及结果说明 (一) 大型事业部制组织人力资源需求预测方法的具体操作 通过对公司内部资料及员工访谈资料的分析,我们可以得出影响组织人员配置的关键业务指标。该下属事业部组织人力资源需求预测主要考虑的就是上述各关键业务指标与员工人数之间的关系。其具体操作见下:(1)将各下属事业部历年的关键业务指标月数据及员工月平均值的原始数据分别输入SPSS中(在数据视图第一列中可设置“时间”,以方便查看);(2) 在SPSS 工具栏中选择“Analyze”→“Regression” → “Linear”; (3) 将员工数放入“Dependent” 一栏中, 关键业务指标则放入“Independent”一栏中;(4)在“Method”一栏中选择 “Stepwise” 方法,其它栏的设置按照软件默认的设置进行;(5)点击“OK”,生成多元逐步回归结果, 由此可以得出影响因变量,即员工数的自变量;(6)将影响各下属事业部员工数的自变量下一年年预测值各自输入 SPSS 界面中;(7)重复上述的第 1 至第 4 步骤(在自变量一栏中可只放入影响员工数的自变量),再点击“Save”,在出现的对话框中,勾选 “Predicted Values” 中的“Unstandardized”;在“Prediction Intervals”一栏中勾选 “Mean”,输入“Confidence Interval”为95%,点击“Continue”;(8)返回“Linear Regression”界面,再点击“OK”,在SPSS数据视图界面中便生成各下属事业部各自下一年的预测人数及均值置信区间。 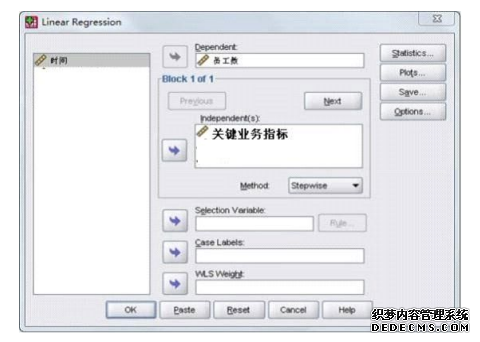 图 4 回归分析过程 (线性回归界面) 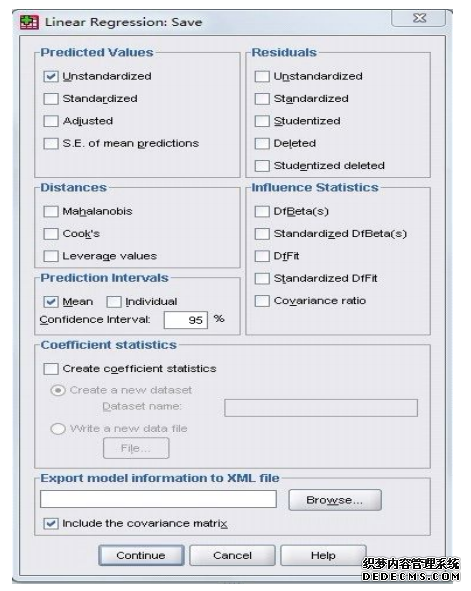 图 5 回归分析过程 (保存界面)
(二) 大型事业部制组织人力资源需求预测的结果说明
虽然代入同样的关键业务指标,各下属事业部所得回归方程中的指标变量可能不尽相同。另外,为什么一些从常识看来本应该对人员总数起主要解释作用的因素,在某些下属事业部的人力资源需求预测模型中被剔除,反而是一些看起来与员工总数关联性不那么强的因素进入了模型?本文具体分析如下: 1.多重共线性。多重共线性是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。方差膨胀因子(Variance Inflation Factor;简称 VIF)越大,显示共线性越严重。当 0<VIF<10,不存在多重共线性;当 10≤VIF<100,存在较强的多重共线性;当 VIF≥100,存在严重多重共线性。需要特别注意的是,如果两个自变量相关系数很大,则一定存在多重共线性,如果相关系数很小,不一定没有多重共线性。 2.多元逐步回归法。各下属事业部回归方程中最终所进入的自变量并不全相同,这是由于各自变量与因变量的关系大小不同即存在上述的多重共线性。而多元逐步回归方法是一种最广泛应用的消除多重共线性方法,它可通过SPSS系统自动剔除部分影响人员数量的变量, 而只保留个别变量以选取“最优”回归方程。如果在操作时使用强制回归,结果可能也符合公司的经验判断,但在统计上会有争议,而SPSS软件在使用多元逐步回归统计分析方法下,可自动过滤掉共线性影响,保证最后进入方程变量的最优性。 六、 结论 每个组织有其自身特有的状况,组织应该根据其实际情况采取相应的人力资源需求预测方法。而影响大型事业部制组织人力资源需求预测的关键因素相对较多,单凭以往的经验来定性地预测企业的人力资源需求是不可行的。为了不只考虑时间或产量等个别因素,并考虑其它多种因素对人力资源的需求影响,本文由此在大型事业部组织进行分类的基础上,对大型组织人力资源需求预测提出了相关建议及操作说明。需要注意的是,在多元逐步回归预测中使用计算机技术非常必要,多元回归计算比较复杂,手工计算耗时多,易出错。尽管该算法对于情况各异的组织来说,也存在一些需要深入探讨的因素,但对于大型事业部组织来说,它不失为一个值得应用的方法。另外,企业也要注意灵活地将定性和定量方法相结合,这样才会产生更为科学合理和符合实际的预测结果。 【参考文献】 [1] 胡江波.CT集团组织结构改进[J].中南大学硕士学位论文,2008. [2] 刘善仕,凌文轩.动态环境中企业人力资源需求预测[J].华南金融研究,2002(6). [3] 孟庆和.多元回归分析中多重共线性的处理[J].中国卫生统计,1997(1) . [4] 吴喜之,卢纹岱.SPSS 统计分析[M].4 版.北京:电子工业出版社,2010. [5] 张红兵,贾来喜,李潞.SPSS 宝典[M].北京:电子工业出版社,2007. [6] 张可明.我国商业银行事业部制改革的探索研究[J].北京交通大学硕士学位论文,2010. [7] 张芳,何薇.企业人力资源需求预测方法探讨[J].人才资源开发,2005(11) . |
| 在线咨询: |
|
| 联系电话: | 18602588568 |
| 投稿邮箱: | bosslunwen@126.com |
| ★诚信★专业★权威★快速★ | |

